![]()
![]()
An implementation of Hastie and Tibshirani’s Discriminant Adaptive Nearest Neighbor Classification in R.
You can install the released version of dann from CRAN with:
In k nearest neighbors, the shape of the neighborhood is always circular. Discriminant Adaptive Nearest Neighbor (dann) is a variation of k nearest neighbors where the shape of the neighborhood is data driven. The neighborhood is elongated along class boundaries and shrunk in the orthogonal direction. See Discriminate Adaptive Nearest Neighbor Classification by Hastie and Tibshirani. This package implements DANN and sub-DANN in section 4.1 of the publication and is based on Christopher Jenness’s python implementation.
In this example, simulated data is made. The overall trend is a circle inside a square.
library(dann)
library(dplyr, warn.conflicts = FALSE)
library(ggplot2)
library(mlbench)
set.seed(1)
#Create training data
train <- mlbench.circle(500, 2) %>%
tibble::as_tibble()
colnames(train) <- c("X1", "X2", "Y")
train <- train %>%
mutate(Y = as.numeric(Y))
ggplot(train, aes(x = X1, y = X2, colour = as.factor(Y))) +
geom_point() +
labs(title = "Train Data", colour = "Y")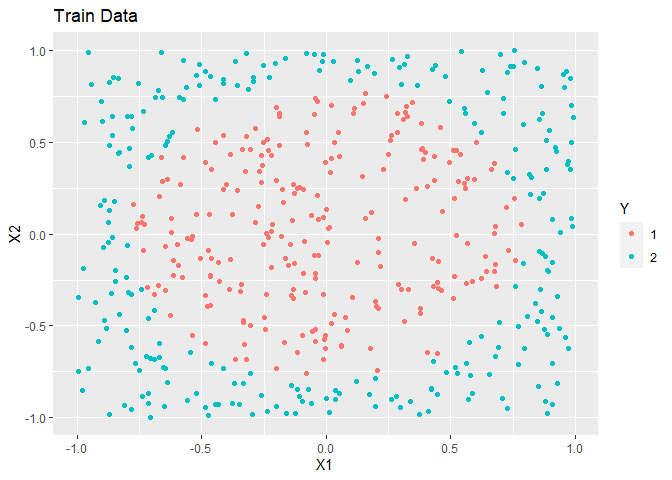
#Create test data
test <- mlbench.circle(500, 2) %>%
tibble::as_tibble()
colnames(test) <- c("X1", "X2", "Y")
test <- test %>%
mutate(Y = as.numeric(Y))
ggplot(test, aes(x = X1, y = X2, colour = as.factor(Y))) +
geom_point() +
labs(title = "Test Data", colour = "Y")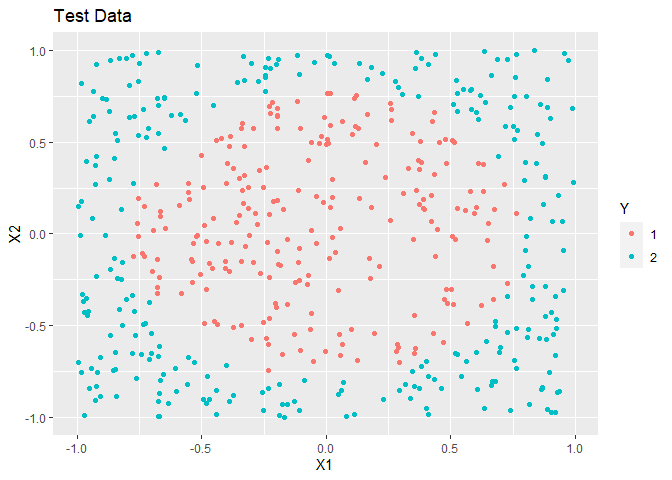
To train a model, the data and a few parameters are passed into dann. Neighborhood_size is the number of data points used to estimate a good shape of the neighborhood. K is the number of data points used in the final classification. Overall, dann is a highly accurate model for this data set.