![]()
![]()
EQ-5D is a popular health related quality of life instrument used in the clinical and economic evaluation of health care. Developed by the EuroQol group, the instrument consists of two components: health state description and evaluation.
For the description component a subject self-rates their health in terms of five dimensions; mobility, self-care, usual activities, pain/discomfort, and anxiety/depression using either a three-level (EQ-5D-3L and EQ-5D-Y) or a five-level (EQ-5D-5L) scale.
The evaluation component requires a patient to record their overall health status using a visual analogue scale (EQ-VAS).
Following assessment the scores from the descriptive component can be reported as a five digit number ranging from 11111 (full health) to 33333/55555 (worst health). A number of methods exist for analysing these five digit profiles. However, frequently they are converted to a single utility index using country specific value sets, which can be used in the clinical and economic evaluation of health care as well as in population health surveys.
The eq5d package provides methods for the cross-sectional and longitudinal analysis of EQ-5D profiles and also the calculation of utility index scores from a subject’s dimension scores. Additionally, a Shiny app is included to enable the calculation, visualisation and automated statistical analysis of multiple EQ-5D index values via a web browser using EQ-5D dimension scores stored in CSV or Excel files.
Value sets for EQ-5D-3L are available for many countries and have been produced using the time trade-off (TTO) valuation technique or the visual analogue scale (VAS) valuation technique. Some countries have TTO and VAS value sets for EQ-5D-3L. Additionally, EQ-5D-3L “reverse crosswalk” value sets published on the EuroQol website that enable EQ-5D-3L data to be mapped to EQ-5D-5L value sets are included.
For EQ-5D-5L, a standardised valuation study protocol (EQ-VT) was developed by the EuroQol group based on the composite time trade-off (cTTO) valuation technique supplemented by a discrete choice experiment (DCE). The EuroQol group recommends users to use a standard value set where available.
The EQ-5D-5L “crosswalk” value sets published by van Hout et al as well as that for Russia are also included. The crosswalk value sets enable index values to be calculated for EQ-5D-5L data where no value set is available by mapping between the EQ-5D-5L and EQ-5D-3L descriptive systems.
The recently published age and sex conditional based mapping data by the NICE Decision Support Unit are also now part of the package. These enable age-sex based EQ-5D-3L to EQ-5D-5L and EQ-5D-5L to EQ-5D-3L mappings from dimensions and exact or approximate utility index scores.
Additional information on EQ-5D can be found on the EuroQol website as well as in Szende et al (2007) and Szende et al (2014). Advice on choosing a value set can also be found on the EuroQol website.
You can install the released version of eq5d from CRAN with:
install.packages("eq5d")And the development version from GitHub with:
# install.packages("devtools")
devtools::install_github("fragla/eq5d")library(eq5d)
#single calculation
#named vector MO, SC, UA, PD and AD represent mobility, self-care, usual activites, pain/discomfort and anxiety/depression, respectfully.
scores <- c(MO=1,SC=2,UA=3,PD=2,AD=1)
#EQ-5D-3L using the UK TTO value set
eq5d(scores=scores, country="UK", version="3L", type="TTO")
#> [1] 0.329
#Using five digit format
eq5d(scores=12321, country="UK", version="3L", type="TTO")
#> [1] 0.329
#EQ-5D-Y using the Slovenian cTTO value set
eq5d(scores=13321, country="Slovenia", version="Y", type="cTTO")
#> [1] 0.295
#EQ-5D-5L crosswalk
eq5d(scores=55555, country="Spain", version="5L", type="CW")
#> [1] -0.654
#EQ-5D-3L reverse crosswalk
eq5d(scores=33333, country="Germany", version="3L", type="RCW")
#> [1] -0.329
#EQ-5D-5L to EQ-5D-3L NICE DSU mapping
#Using dimensions
eq5d(c(MO=1,SC=2,UA=3,PD=4,AD=5), version="5L", type="DSU", country="UK", age=23, sex="male")
#> [1] 0.083
#Using exact utility score
eq5d(0.922, country="UK", version="5L", type="DSU", age=18, sex="male")
#> [1] 0.893
#Using approximate utility score
eq5d(0.435, country="UK", version="5L", type="DSU", age=30, sex="female", bwidth=0.0001)
#> [1] 0.302
#multiple calculations using the Canadian VT value set
#data.frame with individual dimensions
scores.df <- data.frame(
MO=c(1,2,3,4,5), SC=c(1,5,4,3,2), UA=c(1,5,2,3,1), PD=c(1,3,4,3,4), AD=c(1,2,1,2,1)
)
eq5d(scores.df, country="Canada", version="5L", type="VT")
#> [1] 0.949 0.362 0.390 0.524 0.431
#data.frame using five digit format
scores.df2 <- data.frame(state=c(11111,25532,34241,43332,52141))
eq5d(scores.df2, country="Canada", version="5L", type="VT", five.digit="state")
#> [1] 0.949 0.362 0.390 0.524 0.431
#or using a vector
eq5d(scores.df2$state, country="Canada", version="5L", type="VT")
#> [1] 0.949 0.362 0.390 0.524 0.431The available value sets can be viewed using the valuesets function. The results can be filtered by EQ-5D version, value set type or by country.
# Return all value sets (top 6 returned for brevity).
head(valuesets())
#> Version Type Country
#> 1 EQ-5D-3L TTO Argentina
#> 2 EQ-5D-3L TTO Australia
#> 3 EQ-5D-3L TTO Brazil
#> 4 EQ-5D-3L TTO Canada
#> 5 EQ-5D-3L TTO Chile
#> 6 EQ-5D-3L TTO China
# Return VAS based value sets (top 6 returned for brevity).
head(valuesets(type="VAS"))
#> Version Type Country
#> 1 EQ-5D-3L VAS Belgium
#> 2 EQ-5D-3L VAS Denmark
#> 3 EQ-5D-3L VAS Europe
#> 4 EQ-5D-3L VAS Finland
#> 5 EQ-5D-3L VAS Germany
#> 6 EQ-5D-3L VAS Iran
# Return EQ-5D-5L value sets (top 6 returned for brevity).
head(valuesets(version="5L"))
#> Version Type Country
#> 1 EQ-5D-5L VT Belgium
#> 2 EQ-5D-5L VT Canada
#> 3 EQ-5D-5L VT China
#> 4 EQ-5D-5L VT Denmark
#> 5 EQ-5D-5L VT Egypt
#> 6 EQ-5D-5L VT England
# Return all UK value sets.
valuesets(country="UK")
#> Version Type Country
#> 1 EQ-5D-3L TTO UK
#> 2 EQ-5D-3L VAS UK
#> 3 EQ-5D-5L CW UK
#> 4 EQ-5D-3L DSU UK
#> 5 EQ-5D-5L DSU UK
# Return all EQ-5D-5L to EQ-5D-3L DSU value sets.
valuesets(type="DSU", version="5L")
#> Version Type Country
#> 1 EQ-5D-5L DSU China
#> 2 EQ-5D-5L DSU Germany
#> 3 EQ-5D-5L DSU Japan
#> 4 EQ-5D-5L DSU Netherlands
#> 5 EQ-5D-5L DSU SouthKorea
#> 6 EQ-5D-5L DSU Spain
#> 7 EQ-5D-5L DSU UKA number of methods have been published that enable the analysis of EQ-5D profiles, most recently in the open access book Methods for Analysing and Reporting EQ-5D Data by Devlin, Janssen and Parkin. The eq5d package includes R implentations of some of the methods from this book and from other sources that may be of use in analysing EQ-5D data.
The eq5dcf function calculates the frequency, percentage, cumulative frequency and cumulative percentage for each five digit profile in an EQ-5D dataset. Either a vector of five digit profiles or a data.frame of indiviual dimensions can be passed to this function in order to summarise data in this way.
library(readxl)
#load example data
data <- read_excel(system.file("extdata", "eq5d3l_example.xlsx", package="eq5d"))
#run eq5dcf function on a data.frame
res <- eq5dcf(data, "3L")
# Return data.frame of cumulative frequency stats (top 6 returned for brevity).
head(res)
#> State Frequency Percentage CumulativeFreq CumulativePerc
#> 1 11121 36 18.0 36 18.0
#> 2 11111 24 12.0 60 30.0
#> 3 22222 21 10.5 81 40.5
#> 4 22221 18 9.0 99 49.5
#> 5 11221 12 6.0 111 55.5
#> 6 21221 11 5.5 122 61.0The eq5d package includes methods for summarising the severity of EQ-5D health state. The Level Sum Score (LSS) treats each dimension’s level as a number rather than a category. Each number is added up to produce a score between 5 and 15 for EQ-5D-3L and 5 and 25 for EQ-5D-5L.
lss(c(MO=1,SC=2,UA=3,PD=2,AD=1), version="3L")
#> [1] 9
lss(55555, version="5L")
#> [1] 25
lss(c(11111,12345, 55555), version="5L")
#> [1] 5 15 25The Level Frequency Score (LFS) is an alternative method of summarising profile data developed by Oppe and de Charro. Here the frequency of the levels for each health state are characterised. As described in Devlin, Janssen and Parkin’s book, the full health profile 11111 for EQ-5D-5L has 5, 1 s, no level 2, 3, 4 and 5s, so the LFS is 50000; the health profile 55555 is 00005; profiles such as 31524 and 53412 would be 11111.
lfs(c(MO=1,SC=2,UA=3,PD=2,AD=1), version="3L")
#> [1] "221"
lfs(55555, version="5L")
#> [1] "00005"
lfs(c(11111,12345, 55555), version="5L")
#> [1] "50000" "11111" "00005"The Paretian Classification of Health Change (PCHC) was developed by Devlin et al in 2010 and is used to compare changes in individuals over time. PCHC classifies the change in an individual’s health state as better (improvement in at least one dimension), worse (a deterioration in at least one dimension), mixed (improvements and deteriorations in dimensions) or there being no change in the health state. Those classified in the No change group with the 11111 health state can be separated into their own “No problems” group. PCHC can be calculated using the pchc function.
library(readxl)
#load example data
data <- read_excel(system.file("extdata", "eq5d3l_example.xlsx", package="eq5d"))
#use first 50 entries of each group as pre/post
pre <- data[data$Group=="Group1",][1:50,]
post <- data[data$Group=="Group2",][1:50,]
#run pchc function on data.frames
#Show no change, improve, worse, mixed without totals
res1 <- pchc(pre, post, version="3L", no.problems=FALSE, totals=FALSE)
res1
#> Number Percent
#> No change 5 10
#> Improve 32 64
#> Worsen 10 20
#> Mixed change 3 6
#Show totals, but not those with no problems
res2 <- pchc(pre, post, version="3L", no.problems=FALSE, totals=TRUE)
res2
#> Number Percent
#> No change 5 10
#> Improve 32 64
#> Worsen 10 20
#> Mixed change 3 6
#> Total 50 100
#Show totals and no problems for each dimension
res3 <- pchc(pre, post, version="3L", no.problems=TRUE, totals=TRUE, by.dimension=TRUE)
res3
#> $MO
#> Number Percent
#> No change 16 57.1
#> Improve 11 39.3
#> Worsen 1 3.6
#> Total with problems 28 56.0
#> No problems 22 44.0
#>
#> $SC
#> Number Percent
#> No change 10 37.0
#> Improve 14 51.9
#> Worsen 3 11.1
#> Total with problems 27 54.0
#> No problems 23 46.0
#>
#> $UA
#> Number Percent
#> No change 10 25
#> Improve 26 65
#> Worsen 4 10
#> Total with problems 40 80
#> No problems 10 20
#>
#> $PD
#> Number Percent
#> No change 27 57.4
#> Improve 19 40.4
#> Worsen 1 2.1
#> Total with problems 47 94.0
#> No problems 3 6.0
#>
#> $AD
#> Number Percent
#> No change 7 30.4
#> Improve 9 39.1
#> Worsen 7 30.4
#> Total with problems 23 46.0
#> No problems 27 54.0The eq5dds function is an R approximation of the Stata command written by Ramos-Goñi & Ramallo-Fariña. The function analyses and summarises the descriptive components of an EQ-5D dataset. The “by” argument enables a grouping variable to be specified when analysing the data subgroup.
dat <- data.frame(
matrix(
sample(1:3,5*12, replace=TRUE),12,5,
dimnames=list(1:12,c("MO","SC","UA","PD","AD"))
),
Sex=rep(c("Male", "Female"))
)
eq5dds(dat, version="3L")
#> MO SC UA PD AD
#> 1 33.3 25 16.7 25.0 58.3
#> 2 50.0 50 50.0 16.7 25.0
#> 3 16.7 25 33.3 58.3 16.7
eq5dds(dat, version="3L", counts=TRUE)
#> MO SC UA PD AD
#> 1 4 3 2 3 7
#> 2 6 6 6 2 3
#> 3 2 3 4 7 2
eq5dds(dat, version="3L", by="Sex")
#> data[, by]: Female
#> MO SC UA PD AD
#> 1 0.0 33.3 33.3 16.7 100
#> 2 66.7 50.0 16.7 16.7 0
#> 3 33.3 16.7 50.0 66.7 0
#> ------------------------------------------------------------
#> data[, by]: Male
#> MO SC UA PD AD
#> 1 66.7 16.7 0.0 33.3 16.7
#> 2 33.3 50.0 83.3 16.7 50.0
#> 3 0.0 33.3 16.7 50.0 33.3Helper functions are included, which may be useful in the processing of EQ-5D data. getHealthStates returns a vector of all possible five digit health states for a specified EQ-5D version. getDimensionsFromHealthStates splits a vector of five digit health states into a data.frame of their individual components and getHealthStatesFromDimensions combines indiviual dimensions in a data.frame into five digit health states.
# Get all EQ-5D-3L five digit health states (top 6 returned for brevity).
head(getHealthStates("3L"))
#> [1] "11111" "11112" "11113" "11121" "11122" "11123"
# Split five digit health states into their individual components.
getDimensionsFromHealthStates(c("12345", "54321"), version="5L")
#> MO SC UA PD AD
#> 1 1 2 3 4 5
#> 2 5 4 3 2 1Example data is included with the package and can be accessed using the system.file function.
# View example files.
dir(path=system.file("extdata", package="eq5d"))
#> [1] "eq5d3l_example.xlsx" "eq5d3l_five_digit_example.xlsx"
#> [3] "eq5d5l_example.xlsx"
# Read example EQ-5D-3L data.
library(readxl)
data <- read_excel(system.file("extdata", "eq5d3l_example.xlsx", package="eq5d"))
# Calculate index scores
scores <- eq5d(data, country="UK", version="3L", type="TTO")
# Top 6 scores
head(scores)
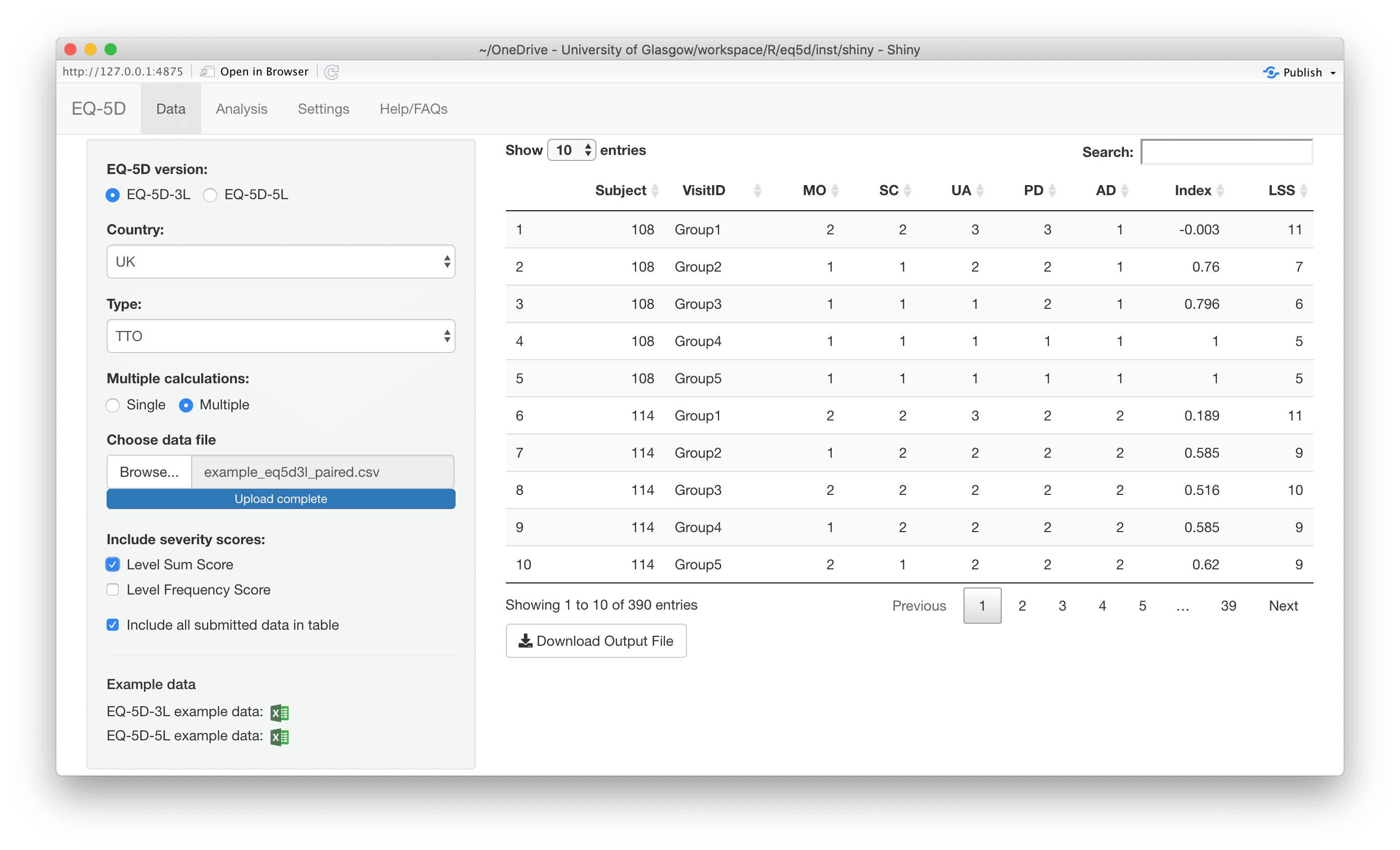
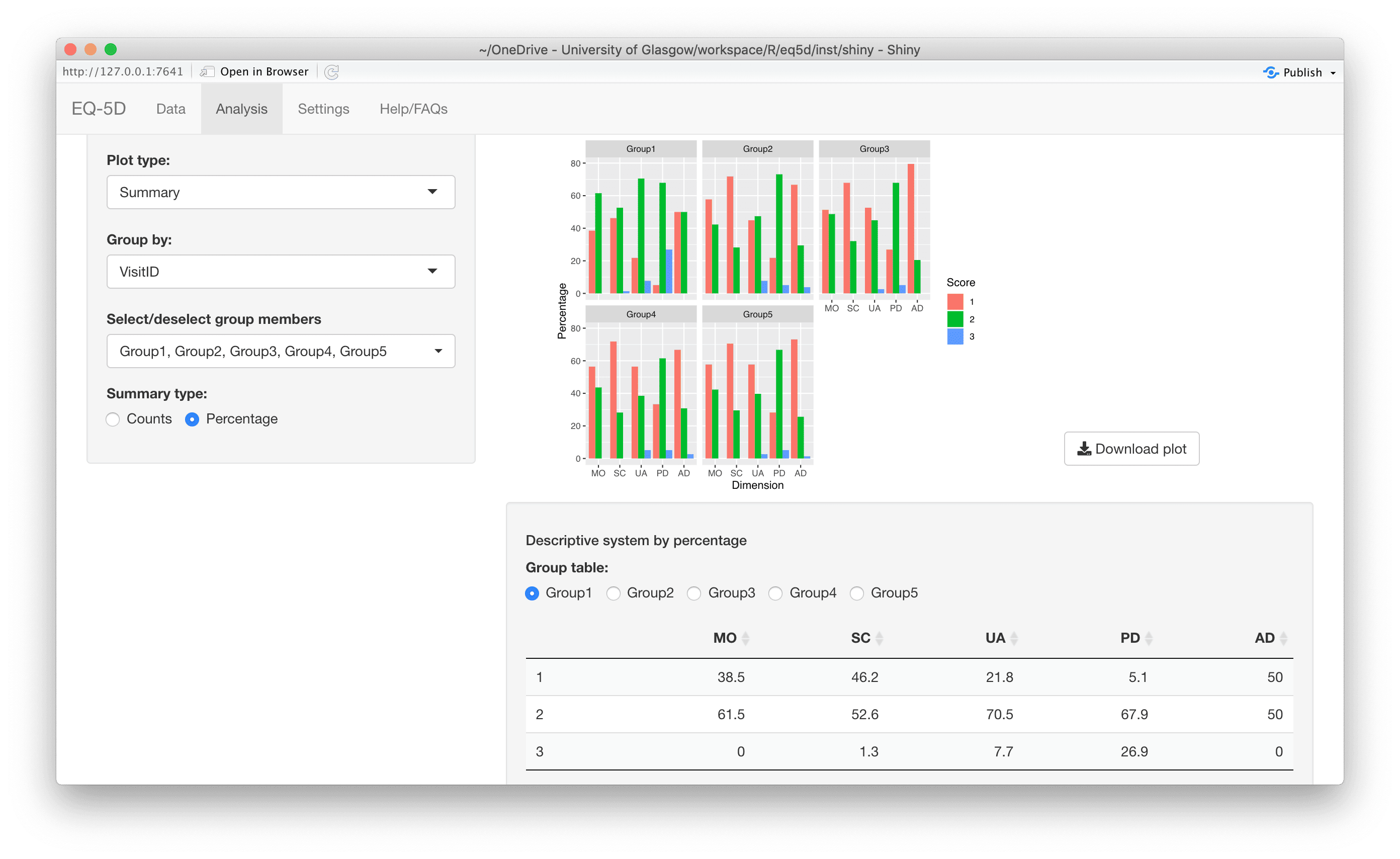
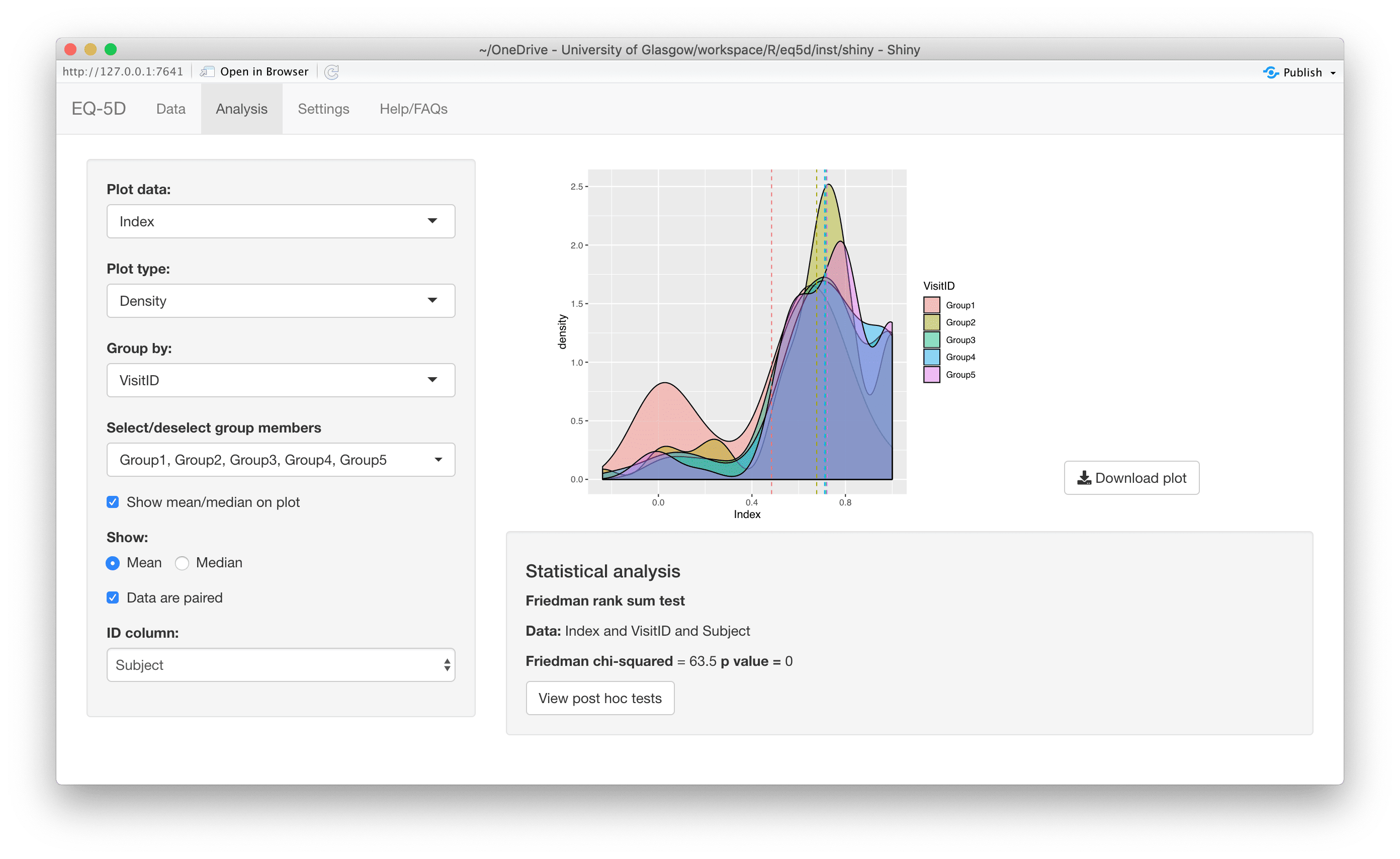
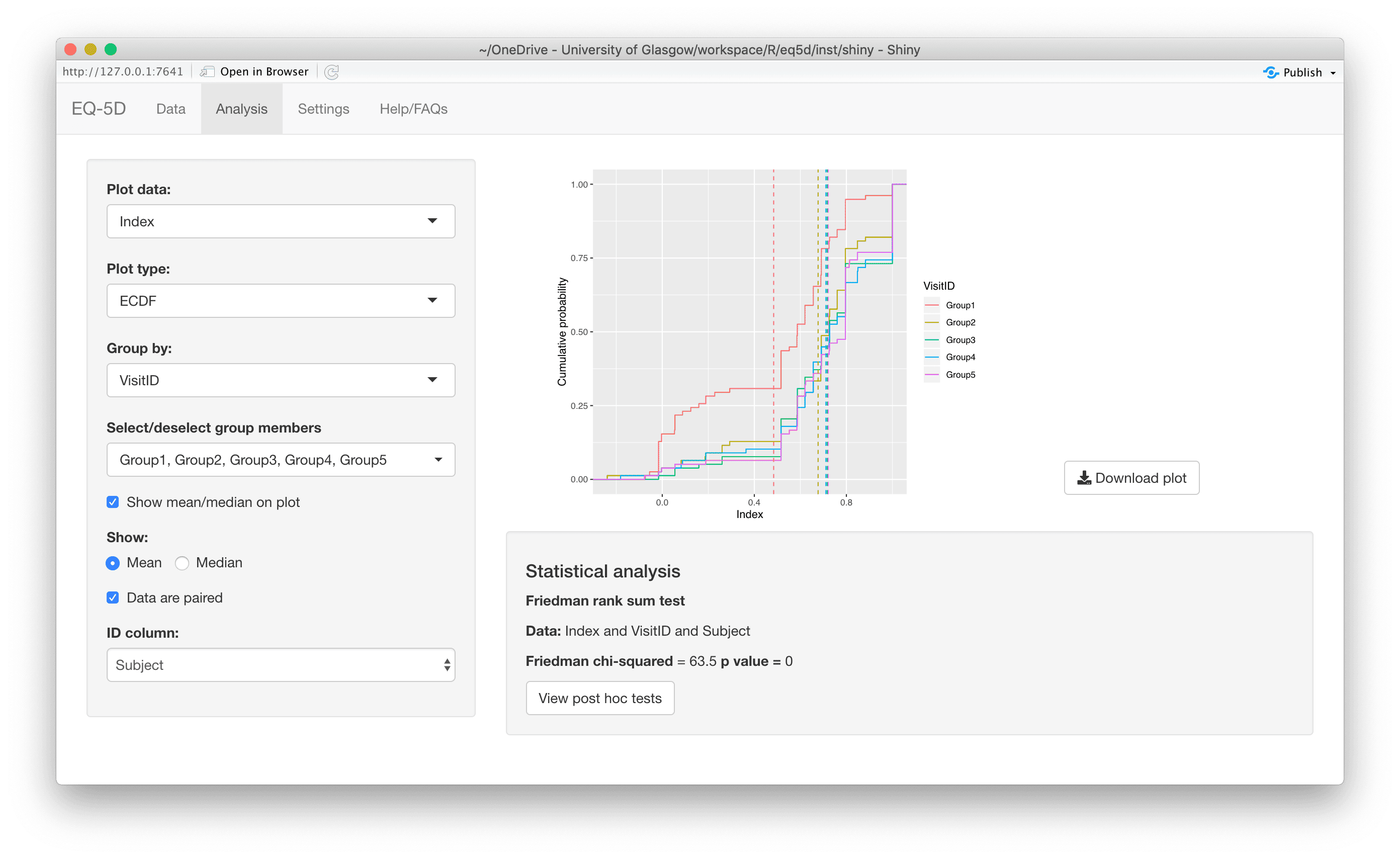
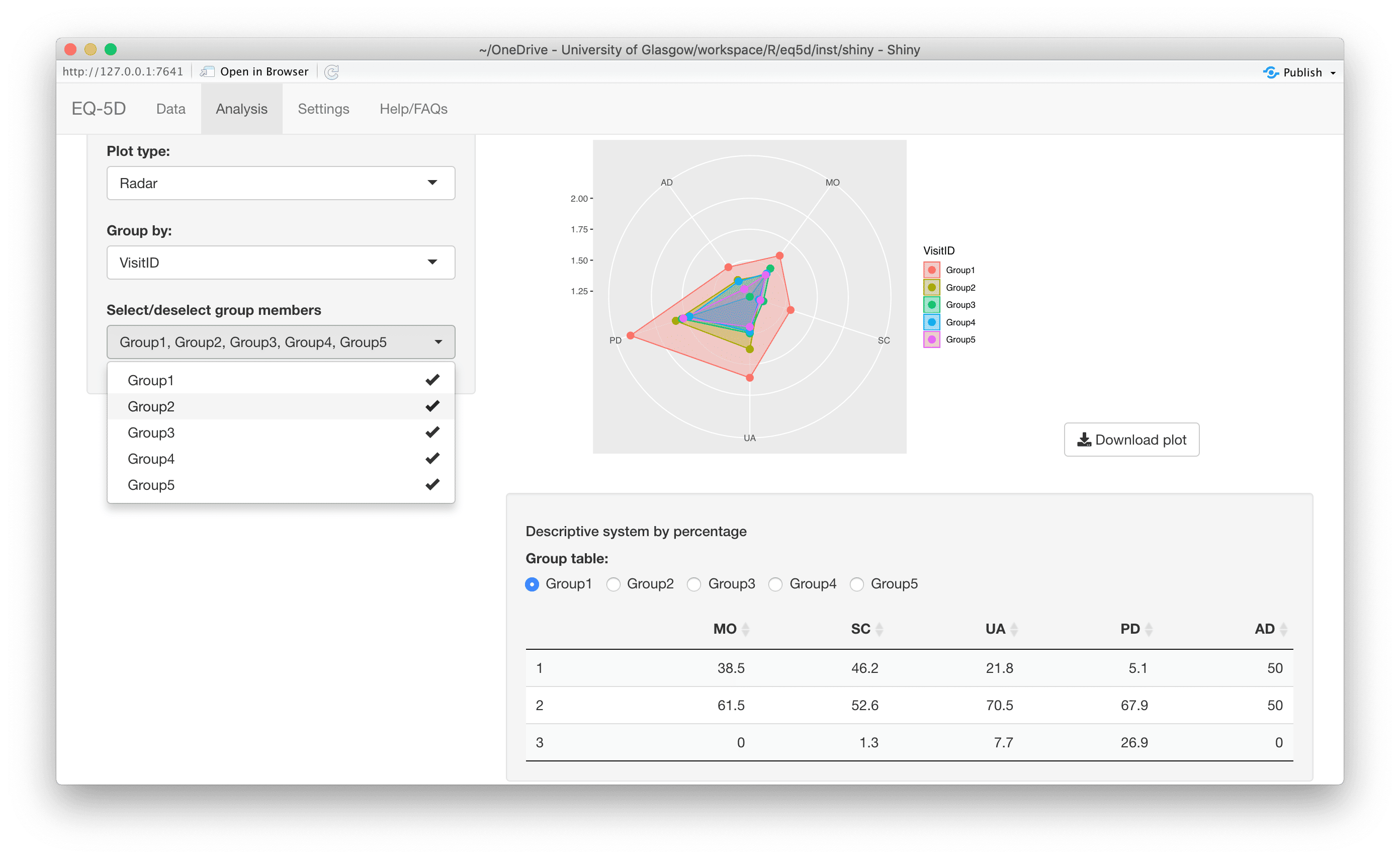
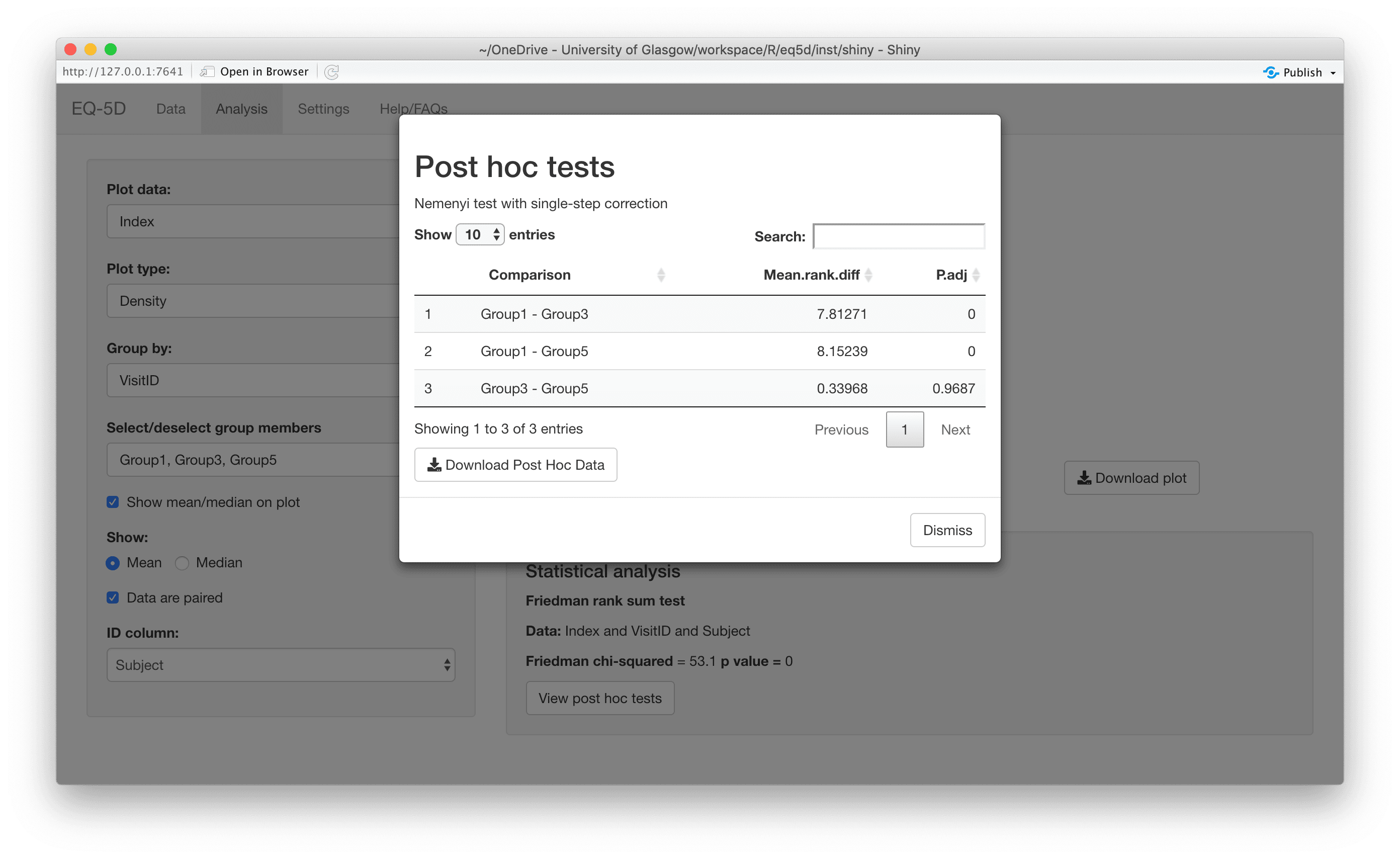
#> [1] 0.760 0.796 -0.003 0.796 0.656 1.000The calculation (and visualisation) of multiple EQ-5D indices can also be performed by upload of a CSV or Excel file using the packaged Shiny app. This requires the shiny, DT, FSA, ggplot2, ggiraph, ggiraphExtra, mime, PMCMRplus, readxl, shinycssloaders and shinyWidgets packages. Ideally the CSV/Excel headers should be the same as the names of the vector passed to the eq5d function i.e. MO, SC, UA, PD and AD or the column name “State” if using the five digit format. However, a modal dialog will prompt the user to select the appropriate columns if the defaults can not be found. Both files below will produce the same results.
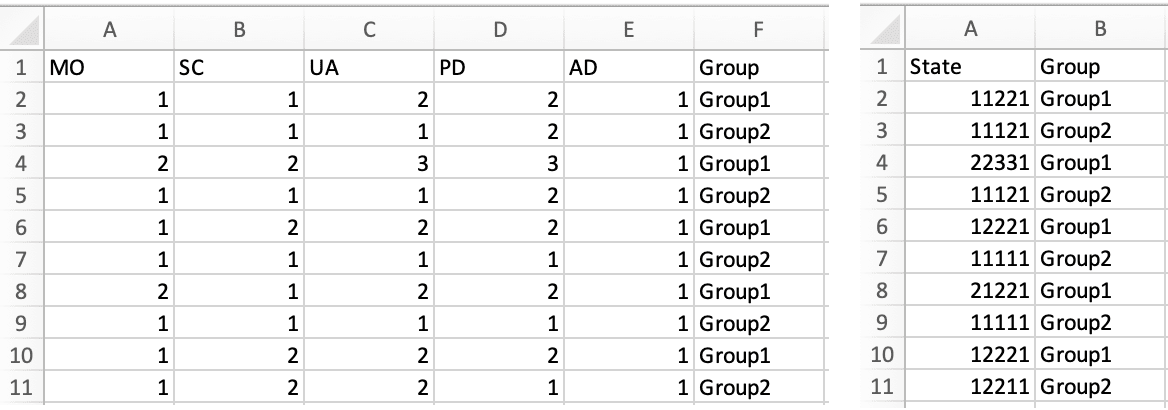
The app is launched using the shiny_eq5d function.
shiny_eq5d()Alternatively, it can be accessed without installing R/Shiny/eq5d by visiting shinyapps.io.
This project is licensed under the MIT License - see the LICENSE.md file for details.