![]()
![]()
The R package fastpos provides a fast algorithm to calculate
the required sample size for a Pearson correlation to stabilize within a
sequential framework (Schönbrodt & Perugini, 2013, 2018). Basically,
one wants to find the sample size at which one can be sure that percent of many studies will fall
into a specified corridor of stability around an assumed population
correlation and stay inside that corridor if more participants are added
to the study. For instance, find out how many participants per
study are required so that, out of 100k studies, 90% would fall into the
region between .4 to .6 (a Pearson correlation) and not leave this
region again when more participants are added (under the assumption that
the population correlation is .5). This sample size is also referred to
as the critical point of stability for the specific
parameters.
This approach is related to the AO-method of sample size planning
(e.g. Algina & Olejnik, 2003) and as such can be seen as an
alternative to power analysis. Unlike AO, the concept of
stability incorporates the idea of sequentially adding
participants to a study. Although the approach is young, it has already
attracted a lot of interest in the psychological research community,
which is evident in over 800 citations of the original publication
(Schönbrodt & Perugini, 2013). Still, to date, there exists no easy
way to use the stability approach for individual sample size planning
because there is no analytical solution to the problem and a simulation
approach is computationally expensive with . The presented
package overcomes this limitation by speeding up the calculation of
correlations and achieving
. For typical parameters,
the theoretical speedup should be at least around a factor of 250. An
empirical benchmark for a typical scenario even shows a speedup of about
460, paving the way for a wider usage of the stability
approach.
You can install the released version of fastpos from CRAN with:
install.packages("fastpos")You can install the development version from GitHub with devtools:
devtools::install_github("johannes-titz/fastpos")Since you have found this page, I assume you either want to (1) calculate the critical point of stability for your own study or (2) explore the method in general. If this is the case, read on and you should find what you are looking for. Let us first load the package and set a seed for reproducibility:
library(fastpos)
RNGkind("L'Ecuyer-CMRG")
set.seed(19950521)In most cases you will just need the function find_critical_pos which will give you the critical point of stability for your specific parameters.
Let us reproduce Schönbrodt and Perugini’s quite famous and oft-cited table of the critical points of stability for a precision of 0.1. We reduce the number of studies to 10k and use multicore support (only works under GNU/Linux) so that it runs fairly quickly.
n_cores <- parallel::detectCores()
find_critical_pos(rho = seq(.1, .7, .1), sample_size_max = 1e3,
n_studies = 10e3, n_cores = n_cores)
#> Warning in find_critical_pos(rho = seq(0.1, 0.7, 0.1), sample_size_max = 1000, :
#> 40 simulation[s] did not reach the corridor of stability.
#> Increase sample_size_max and rerun the simulation.
#> rho_pop pos.80% pos.90% pos.95% sample_size_min sample_size_max lower_limit
#> 1 0.1 249.0 361 479.00 20 1000 0.0
#> 2 0.2 238.2 342 446.00 20 1000 0.1
#> 3 0.3 214.0 309 411.00 20 1000 0.2
#> 4 0.4 178.0 257 341.00 20 1000 0.3
#> 5 0.5 143.0 204 271.00 20 1000 0.4
#> 6 0.6 105.0 151 201.00 20 1000 0.5
#> 7 0.7 65.0 94 126.05 20 1000 0.6
#> upper_limit n_studies n_not_breached precision_absolute precision_relative
#> 1 0.2 10000 23 0.1 NA
#> 2 0.3 10000 13 0.1 NA
#> 3 0.4 10000 3 0.1 NA
#> 4 0.5 10000 1 0.1 NA
#> 5 0.6 10000 0 0.1 NA
#> 6 0.7 10000 0 0.1 NA
#> 7 0.8 10000 0 0.1 NAThe results are very close to Schönbrodt and Perugini’s table (see https://github.com/nicebread/corEvol). Note that a warning is shown, because in some simulations the corridor of stability was not reached. As long as this number is low, this should not affect the estimates much. But if you want to get more accurate estimates, then increase the maximum sample size.
If you want to dig deeper, you can have a look at the functions that find_critical_pos builds upon. simulate_pos is the workhorse of the package. It calls a C++ function to calculate correlations sequentially and it does this pretty quickly (but you know that already, right?). A rawish approach would be to create a population with create_pop and pass it to simulate_pos:
pop <- create_pop(0.5, 1e6)
pos <- simulate_pos(x_pop = pop[,1],
y_pop = pop[,2],
n_studies = 1e4,
sample_size_min = 20,
sample_size_max = 1e3,
replace = T,
lower_limit = 0.4,
upper_limit = 0.6,
progress = FALSE)
hist(pos, xlim = c(0, 1e3), xlab = c("Point of stability"),
main = "Histogram of points of stability for rho = .5+-.1")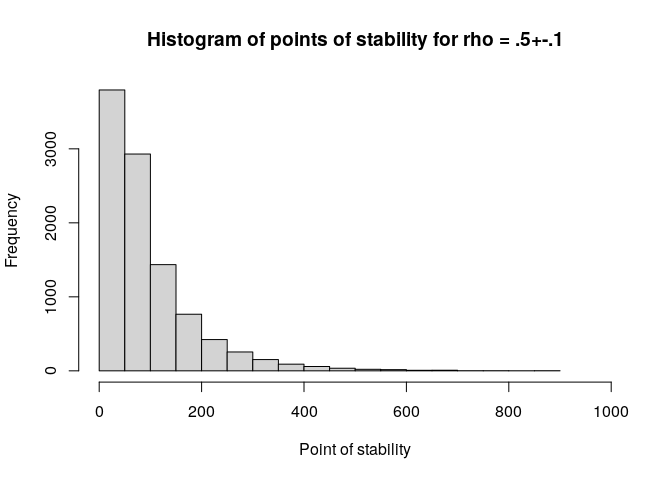
quantile(pos, c(.8, .9, .95), na.rm = T)
#> 80% 90% 95%
#> 146.0 209.1 280.0Note that no warning message appears if the corridor is not reached, but instead an NA value is returned. Pay careful attention if you work with this function, and adjust the maximum sample size as needed.
create_pop creates the population matrix by using a method described on SO (https://stats.stackexchange.com/questions/15011/generate-a-random-variable-with-a-defined-correlation-to-an-existing-variables/15040#15040). This is a much simpler way than Schönbrodt and Perugini’s approach, but the results do not seem to differ. If you are interested in how population parameters (e.g. skewness) affect the point of stability, you should instead refer to the population generating functions in Schönbrodt and Perugini’s work.
Since version 0.4.0 fastpos supports multiple cores. My first attempts to implement this were quite unsuccessful because of several reasons: (1) Higher-level parallelism in R makes it difficult to show progress in C++, which is where the important and time-demanding calculations happen (2) some parallelizing solutions do not work on all operating systems (e.g. mcpbapply) (3) overhead can be quite large, especially for a small number of simulation runs.
I thought the best solution is is to directly parallelize in C++. I tried to do it with RcppThread, but in the end this was even slower than singlethreading. I assume that a more experienced C++ programmer could make it work but to me parallelizing in C++ feels a bit like torture.
My intermediate solution was quite simple and pragmatic: to use
futures. I divided the number of studies by the available cores
, then started
simulations via futures in a multisession plan.
Meanwhile the main R process also started a simulation, which showed a
progress bar in C++. All simulations ended at approximately the same
time, the progress bar finished and the futures resolved. The points of
stability were combined and the rest of the program worked as for the
singlethreaded version.
Unfortunately this solution did not bring any substantial speed benefits. Since version 0.5.0 I switched to the parallel package and pbapply. This means there is no multicore support for Windows but the implementation is simple and shows substantial speed benefits.
Even for small simulations these benefits are clearly visible:
onecore <- function() {
find_critical_pos(0.5)
}
multicore <- function() {
find_critical_pos(0.5, n_cores = n_cores)
}
microbenchmark::microbenchmark(onecore(), multicore(), times = 10)
#> Unit: milliseconds
#> expr min lq mean median uq max neval
#> onecore() 823.6173 889.5421 917.1853 923.8258 950.8830 967.0792 10
#> multicore() 383.7214 400.3065 457.7556 443.7456 467.8412 653.1855 10The test was done on a server with 32 cores.
In the introduction I boldly claimed that fastpos is much faster than the original implementation of Schönbrodt and Perugini (corEvol). The theoretical argument goes as follows:
corEvol calculates every correlation from scratch. If we take the sum formula for the correlation coefficient
we can see that several sums are calculated, each consisting of
adding up (the sample size) terms. This has to be done for
every sample size from the minimum to the maximum one. Thus, the total
number of added terms for one sum is:
On the other hand, fastpos calculates the correlation for
the maximum sample size first. This requires to add numbers for one sum. Then it subtracts one value
from this sum to find the correlation for the sample size
, which happens repeatedly until the minimum
sample size is reached. Overall the total number of terms for one sum
amounts to:
The ratio between the two approaches is:
For the typically used of 1000 and
of 20, we can expect a
speedup of about 250. This is only an approximation for several reasons.
First, one can stop the process when the corridor is reached, which is
done in fastpos but not in corEvol. Second, the main
function of fastpos was written in C++ (via Rcpp),
which is much faster than R. At the same time, the algorithms involve
many more steps than just calculating correlations. For instance,
setting up the population with a specific
takes some time since it usually consists of
a million value pairs. The interface functions to setup the simulations
also play an important role. Obviously, there is a lower time limit that
cannot be beat. Thus, it is necessary to study the speed benefit
empirically.
The theoretical difference is so big that it should suffice to give a rough benchmark for which the following parameters were chosen: rho = .1, sample_size_max = 1000, sample_size_min = 20, n_studies = 10000.
Note that corEvol was written as a script for a simulation study and thus cannot be simply called via a function. Furthermore, a simulation run takes a lot of time and thus it is not practical to run it too many times. If you want to experiment with the benchmark, I have forked the original corEvol repository and made a benchmark branch (note that this will only work on GNU/Linux, since here I am using git through the bash):
git -C corEvol pull || git clone --single-branch --branch benchmark \
https://github.com/johannes-titz/corEvolFor corEvol, two files are “sourced” for the benchmark. The first file generates the simulations and the second is for calculating the critical point of stability. I turned off all messages produced by these source files.
library(microbenchmark)
setwd("corEvol")
corevol <- function() {
source("01-simdata.R")
source("02-analyse.R")
}
fastpos <- function() {
find_critical_pos(rho = .1, sample_size_max = 1e3, n_studies = 10e3)
}
bm <- microbenchmark(corevol = corevol(), fastpos = fastpos(), times = 10,
unit = "s")
#>
#> Attache Paket: 'dplyr'
#> Die folgenden Objekte sind maskiert von 'package:stats':
#>
#> filter, lag
#> Die folgenden Objekte sind maskiert von 'package:base':
#>
#> intersect, setdiff, setequal, union
#> Lade nötiges Paket: foreach
#> Lade nötiges Paket: iterators
#> Lade nötiges Paket: parallel
bm
#> Unit: seconds
#> expr min lq mean median uq
#> corevol 365.2412020 366.1631864 368.7407814 369.2972685 370.7415254
#> fastpos 0.7788808 0.7887345 0.8018911 0.7970768 0.8193799
#> max neval
#> 372.3858468 10
#> 0.8325055 10For the chosen parameters, fastpos is about 460 times faster
than corEvol, for which there are two main reasons: (1)
fastpos is built around a C++ function via Rcpp and
(2) this function does not calculate every calculation from scratch, but
only calculates the difference between the correlation at sample size
and
via the sum formula of the Pearson correlation
(see above). There are some other factors that might play a role, but
they cannot account for the large difference found. For instance,
setting up a population takes quite long in corEvol (about
20s), but compared to the ~6 min required overall, this is only a small
fraction. There are other parts of the corEvol code that are
fated to be slow, but again, a speedup by a factor of 460 cannot be
achieved by improving these parts. The presented benchmark is definitely
not comprehensive, but only demonstrates that fastpos can be
used with no significant waiting time for a typical scenario, while for
corEvol this is not the case.
In this case fastpos will return an NA value for the point of stability. When calculating the quantiles, fastpos will use the maximum sample size, which is a more reasonable estimate than ignoring the specific simulation study altogether.
If the same parameters are used, the differences are rather small. In general, differences cannot be avoided entirely due to the random nature of the whole process. Even if the same algorithm is used, the estimates will vary slightly from run to run. The other more important aspect is how studies are treated where the point of stability is not reached: corEvol ignores them, while fastpos assumes that the corridor was reached at the maximum sample size. Thus, if the parameters are the same, fastpos will tend to produce larger estimates, which is more accurate (and more conservative). But note that if the corridor of stability is not reached, then you should increase the maximum sample size. Previously, this was not feasible due to the computational demands, but with fastpos it usually can be done.
If you find any bugs, please use the issue tracker at:
https://github.com/johannes-titz/fastpos/issues
If you need answers on how to use the package, drop me an e-mail at johannes at titz.science or johannes.titz at gmail.com
Comments and feedback of any kind are very welcome! I will thoroughly consider every suggestion on how to improve the code, the documentation, and the presented examples. Even minor things, such as suggestions for better wording or improving grammar in any part of the package, are more than welcome.
If you want to make a pull request, please check that you can still build the package without any errors, warnings, or notes. Overall, simply stick to the R packages book: https://r-pkgs.org/