![]()
![]()
![]()
feasts provides a collection of tools for the analysis of time series data. The package name is an acronym comprising of its key features: Feature Extraction And Statistics for Time Series.
The package works with tidy temporal data provided by the tsibble package to produce time series features, decompositions, statistical summaries and convenient visualisations. These features are useful in understanding the behaviour of time series data, and closely integrates with the tidy forecasting workflow used in the fable package.
You could install the stable version from CRAN:
You can install the development version from GitHub with:
library(feasts)
library(tsibble)
library(tsibbledata)
library(dplyr)
library(ggplot2)
library(lubridate)Visualisation is often the first step in understanding the patterns in time series data. The package uses ggplot2 to produce customisable graphics to visualise time series patterns.
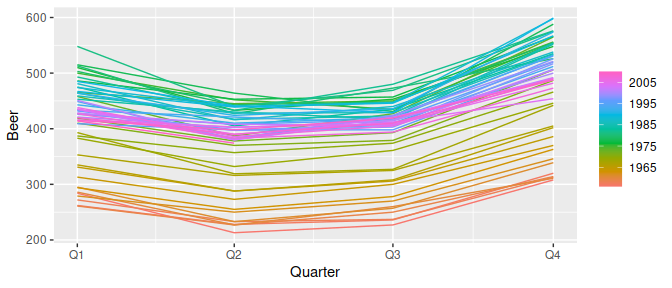
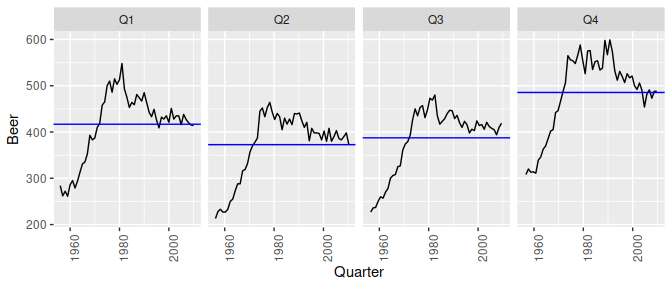
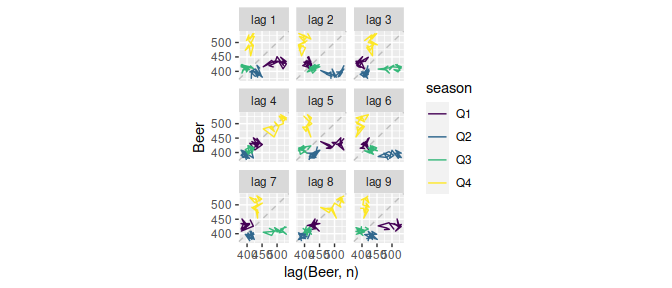
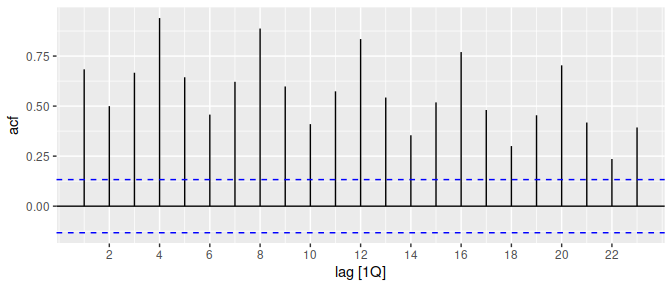
A common task in time series analysis is decomposing a time series into some simpler components. The feasts package supports two common time series decomposition methods:
dcmp <- aus_production %>%
model(STL(Beer ~ season(window = Inf)))
components(dcmp)
#> # A dable: 218 x 7 [1Q]
#> # Key: .model [1]
#> # STL Decomposition: Beer = trend + season_year + remainder
#> .model Quarter Beer trend season_year remainder season_adjust
#> <chr> <qtr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 STL(Beer ~ season(window = Inf)) 1956 Q1 284 272. 2.14 10.1 282.
#> 2 STL(Beer ~ season(window = Inf)) 1956 Q2 213 264. -42.6 -8.56 256.
#> 3 STL(Beer ~ season(window = Inf)) 1956 Q3 227 258. -28.5 -2.34 255.
#> 4 STL(Beer ~ season(window = Inf)) 1956 Q4 308 253. 69.0 -14.4 239.
#> 5 STL(Beer ~ season(window = Inf)) 1957 Q1 262 257. 2.14 2.55 260.
#> 6 STL(Beer ~ season(window = Inf)) 1957 Q2 228 261. -42.6 9.47 271.
#> 7 STL(Beer ~ season(window = Inf)) 1957 Q3 236 263. -28.5 1.80 264.
#> 8 STL(Beer ~ season(window = Inf)) 1957 Q4 320 264. 69.0 -12.7 251.
#> 9 STL(Beer ~ season(window = Inf)) 1958 Q1 272 266. 2.14 4.32 270.
#> 10 STL(Beer ~ season(window = Inf)) 1958 Q2 233 266. -42.6 9.72 276.
#> # … with 208 more rows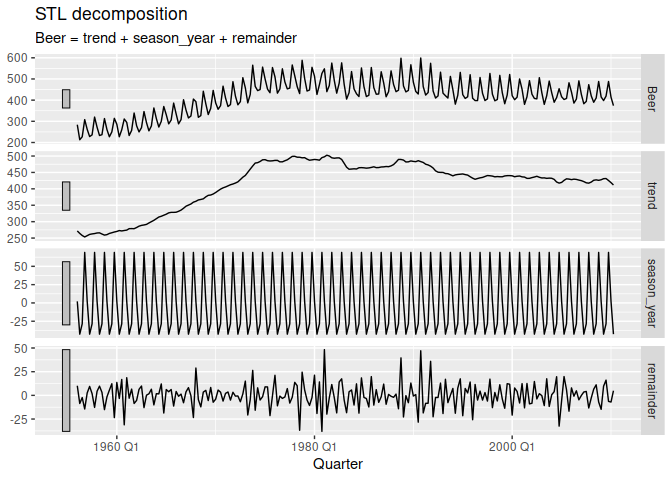
Extract features and statistics across a large collection of time series to identify unusual/extreme time series, or find clusters of similar behaviour.
aus_retail %>%
features(Turnover, feat_stl)
#> # A tibble: 152 x 11
#> State Industry trend_strength seasonal_streng… seasonal_peak_y… seasonal_trough… spikiness
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Aust… Cafes, … 0.989 0.537 0 10 6.15e-5
#> 2 Aust… Cafes, … 0.993 0.610 0 10 1.12e-4
#> 3 Aust… Clothin… 0.990 0.918 9 11 4.77e-6
#> 4 Aust… Clothin… 0.992 0.952 9 11 2.06e-5
#> 5 Aust… Departm… 0.975 0.977 9 11 2.79e-5
#> 6 Aust… Electri… 0.991 0.929 9 11 3.03e-5
#> 7 Aust… Food re… 0.999 0.882 9 11 2.74e-4
#> 8 Aust… Footwea… 0.980 0.937 9 11 5.54e-6
#> 9 Aust… Furnitu… 0.980 0.669 9 1 4.66e-5
#> 10 Aust… Hardwar… 0.992 0.895 9 4 1.47e-5
#> # … with 142 more rows, and 4 more variables: linearity <dbl>, curvature <dbl>, stl_e_acf1 <dbl>,
#> # stl_e_acf10 <dbl>This allows you to visualise the behaviour of many time series (where the plotting methods above would show too much information).
aus_retail %>%
features(Turnover, feat_stl) %>%
ggplot(aes(x = trend_strength, y = seasonal_strength_year)) +
geom_point() +
facet_wrap(vars(State))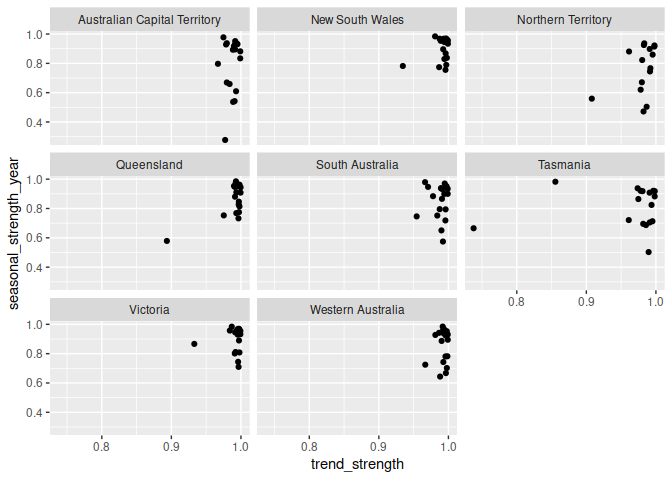
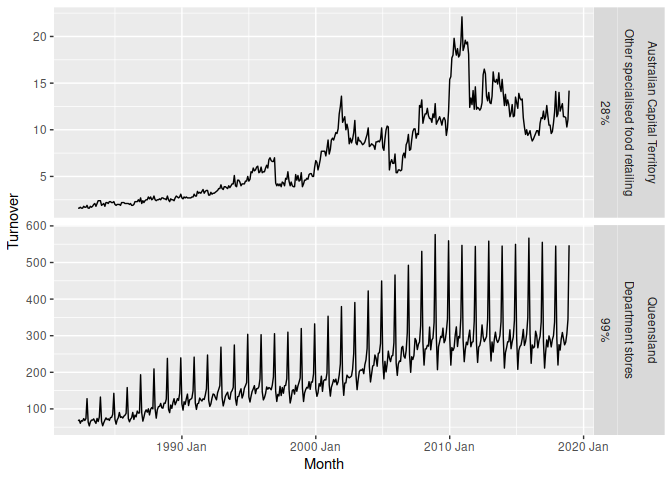
Most of Australian’s retail industries are highly trended and seasonal for all states.
It’s also easy to extract the most (and least) seasonal time series.
extreme_seasonalities <- aus_retail %>%
features(Turnover, feat_stl) %>%
filter(seasonal_strength_year %in% range(seasonal_strength_year))
aus_retail %>%
right_join(extreme_seasonalities, by = c("State", "Industry")) %>%
ggplot(aes(x = Month, y = Turnover)) +
geom_line() +
facet_grid(vars(State, Industry, scales::percent(seasonal_strength_year)),
scales = "free_y")