
In medical research, it is common for researchers to gather data from multiple sources. However, due to privacy concerns (e.g. HIPAA) or the propitiatory nature of the data, one or more of the potential sources may not be in a position to share the data. Various methods have been proposed in the literature, and some R packages have been written (e.g distcomp, ppmHR), which allow analyses to be performed on distributed data in a secure setting. That is, the analyses are performed as if the data were aggregated, but in reality each data partner maintains control over their own data and only shares high level statistics in such a way that the original data cannot be deduced by the other data partners.
Each of these methods assumes that the data is horizontally partitioned. That is, each data partner has the same response variable and covariates for distinct cohorts. What makes this package novel is that we assume that the data is vertically partitioned. That is, each data partner holds a set of unique covariates for the same cohort of observations. (One way to think about this is with horizontally partitioned data, the observation matrix is partitioned by horizontal lines and in vertically partitioned data, the observation matrix is partitioned by vertical lines.)
In this package, we implement three different protocols for vertical distributed regression analysis (VDRA) in a secure setting. They are called 2-party, 2T-party, and kT-party. Each of these protocols can be used to perform linear, logistic, and Cox regression. The purpose of this vignette is to demonstrate how to use this package, so we will not go into details of the protocols and algorithms here. Specific information on the algorithms and a discussion of their security can be found in the following papers:
This package was designed to run in Base-R. However, there are select cases when using functions from the survival package is possible. In these cases, if the survival package is installed, those functions will be used, otherwise, we use our own functions.
When using this package on PopMedNet, the computations can take tens of minutes for linear regression on a data set with a few thousand observations, to hours for Cox regression on a data set with hundreds of thousands, or millions of observations. Even when running the simulation on your local computer using the PopMedNet simulator pmn(), the computations can take several minutes. These times are due to the large about of data that needs to be transferred back and forth between the data partners in order to ensure that the computations are secure and that there is no data leakage. If one were able to aggregate the data from the different data sources without concern for privacy, then they would do so and use more efficient functions. However, there is no free lunch, and the price for security and privacy is time. So, when working through the examples in this vignette, grab a drink, put on some nice music, and find pleasure in the journey.
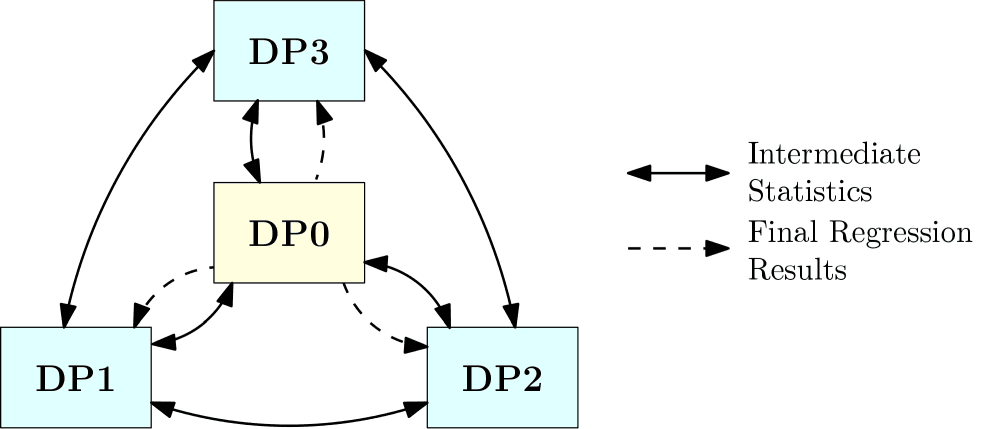
With 2-party VDRA, there are only two data holders, DP0 and DP1 (short for “Data Partner 0” and “Data Partner 1”). This protocol allows DP0 and DP1 to communicate directly with each other, but they never share patient level data with each other nor information which would allow the other party to deduce patient level information. DP0 and DP1 share intermediate statistics with each other multiple times in an iterative manner until the final regression results are computed by DP0 and shared with DP1. A pictorial representation of the data flow between the parties is shown below.
The name DP0 indicates which party is acting as the analysis center. This is the only protocol where the analysis center also provides data. For the next two protocols, the analysis center does not provide any data.
With 2T-party VDRA, there are only two data holders, DP1 and DP2, and an analysis center, DP0. DP1 and DP2 cannot communicate directly with each other, but all communication must pass through DP0. DP0 is a trusted third party that helps facilitate communication and performs much of the computation that was performed by DP1 in the 2-party protocol. Whenever possible, any intermediate statistics shared with DP0 from one data partner (never patient level data) are multiplied by a random orthonormal matrix before being sent to the other data partner. This adds an extra layer of security at the expense of sending more data. The final regression results are computed by DP0 and shared with DP1 and DP2. A pictorial representation of the data flow between the parties is shown below.

With KT-party VDRA, there are two or more data holders, DP1, DP2, … DPk, and one analysis center, DP0. We have tested the package with up to 10 data holders, but there is no reason why there could not be more. With this protocol, all data partners are able to communicate with each other with the benefit that less data is transferred. As with 2T-party VDRA, DP0 facilitates the computations and computes the final regression results, which are then sent to all the data partners. The one possible concern with this method is that a data breach at both the analysis center and one of the data partners could expose another data partner’s data, even though neither the analysis center nor any data partner have enough information to reconstruct any part of any other data partners’ data on their own. A pictorial representation of the data flow between the parties is shown below.
PopMedNet (https://www.popmednet.org/), short for Population Medicine Network, is a “scalable and extensible open-source informatics platform designed to facilitate the implementation and operation of distributed health data networks.” PopMedNet is maintained by Department of Population Medicine at the Harvard Medical School and the Harvard Pilgrim Health Care Institute. Through two generous National Institute of Health Grants, we were able to make modifications to PopMedNet which allowed us to transmit data between data partners in a secure and automatic fashion. These modification were made specifically with the intent of the creation of this package. While this package has been designed to work seamlessly with PopMedNet as a means of communication, it should be possible to use other file transfer software to perform the same task.
If a group of data partners wishes to use PopMedNet and this package for analysis of vertically distributed data, please refer to the vignette How to use the vdra package with PopMedNet for further information. However, for the individuals which are interested in testing out the package to see how it works, a PopMedNet simulator, pmn(), has been supplied as part of the package. This allows the individual to play the part of the all the data partners and the analysis center on a single computer in order to gain an understanding of how to use the package before implementation in a real world setting.
We demonstrate the usage of this package using pmn() as the file transfer protocol for 2-party, 2T-party, and KT-party situations. Take careful note the use of the parameter popmednet = FALSE in all function calls. When popmednet = TRUE is used, an offset is added to make sure that when two or more data partners are running in parallel, there is a at least a 15 second window between when they signal PopMedNet that they are ready to upload files. There are technical reasons for this that are specific to PopMedNet, but are not applicable when other file transfer protocols are utilized.
The VDRA package comes with a data set vdra_data which contains simulated data from a BMI study by the Harvard School of Medicine. The data in vdra_data are not fit for scientific research, but are rather provided as an example for use when learning to use this package. The data contains information from 5,740 subjects with four possible response variables and seven covariates.
The four response variables are:
| Variable(s) | Intended Use |
|---|---|
| Change_BMI | Linear Regression |
| WtLost | Logistic Regression |
| Time, Status | Cox Regression |
If each data partner is using their own data, it is assumed that each data partner has the same number of observations and that observations on corresponding rows are for the same patient. In other words, it is assumed that the data are already aligned according to some common key, and it will be treated as such. Additionally, it is expected that the data will have already been cleaned and only valid values are presented. Some checking of the data is performed by the package, including looking for missing values. During this step, if any problems are found a descriptive error message will be given and the program will terminate.
The directories in which each data partner reads and writes files is fairly rigid, but the home location where these directories are placed is up to the user. For this vignette, we set the base directory to be ~/vdra, but in practice, you can name it whatever you want and place it wherever you desire. This directory is passed as a parameter to pmn() and the data partners, and they assume that it exists. If it does not, they terminate execution. At this point, please create your work directory before proceeding.
Before each run, ~/vdra and all of its subdirectories should not contain any file named files_done.ok, job_done.ok, or job_fail.ok. These are special files that signal PopMedNed (and the simulator) that files have been transferred from another data partner, are ready to be transferred to another data partner, or that the computation has completed or failed. In the event of a normal program termination, these files are removed automatically, but in the event of a program crash or other unplanned events, one or more of these files may be left behind which could have unintended consequences the next time that a simulation is run. Because of this, we suggest that all files are deleted from ~/pmn each time you run a simulation.
When is run the first time (where k is some positive integer signaling how many parties (data partners and the analysis center) are going to participate in the computation, it first checks that ~/vdra exists and then it creates the subdirectories dp0, dp1, through dp(k) in the directory ~/vdra. Each subdirectory contains the further subdirectories inputfiles, msoc, msoc1, …, msoc(k). All files that Data Partner n wants transferred to another data partner are written to ~/vdra/dp(n)/inputfiles. On the other hand, ~/vdra/dp(n)/msoc contains the files sent to Data Partner n by the analysis center (Data Partner 0) and ~/vdra/dp(n)/msoc(m) contains the files sent to Data Partner n by Data Partner m.
As pmn() (or PopMedNet if you are using that) and the data partners all run in parallel, we now outline the order of execution. For simplicity, assume that we have the analysis center (Data Partner 0) and data partners 1 and 2. When we first start the scripts, data partners 1 and 2 are active. They do some computations and then write files to their respective directory inputfiles, along with a file file_list.csv which indicates which files are to be sent to which data partners. A data partner can transfer a file to any other data partner within the limitations of the protocol being used, the only additional exception being that they cannot transfer a file to themselves. Finally, they write files_done.csv which indicates to pmn() (PopMedNet) that the files are ready to be transfered. Once all active data partners have written files_done.csv, pmn() (PopMedNet) transfers the files to the appropriate read directories of the appropriate data partners. Once the files are transferred, pmn() (PopMedNet) writes files_done.csv in each directory that received a file. Each data partner that received a file is now active. The active data partners delete the various files_done.csv, read the input files, process, write files, and the process continues. The process ends when the analysis center determines that the computation is over. At this point, the analysis center writes the file job_done.ok in the case of a successful computation, or job_fail.ok in the case of an unsuccessful computation. This signals pmn() (PopMedNet) to tell all the other data partners to shutdown and then pmn() (PopMedNet) shuts down itself.
The next sections of the vignette demonstrate how to use this package to perform parallel computations.
For 2-party Vertically Distributed Regression, we will run three sessions of R simultaneously. If you are using R-Studio, you can open up two more sessions of R-Studio by choosing the menu item Session→New Session. The first session will run the PopMedNet Simulator, pmn(), and the other two sessions will run the analysis center (Data Partner 0) and the Data Partner 1, respectively. Once you run one block of code in a session of R, immediately move to the next R session to execute the next block of code. The scripts interact in such a way that they all need to run in parallel for the the computation to proceed to completion.
In our code, we assume that we run pmn() first, as this simulates PopMedNet being run first, which delivers the requests in a real-world setting. Before you run pmn(), be sure that ~/vdra is empty (or at least does not contain any files of the form *.ok. When we run pmn(), we tell it that there will be one data partner beyond the analysis center and that the working directory is ~/vdra.
At this point, pmn() will have created directories ~/vdra/dp0 and ~/vdra/dp1 which are used in the communication process. For this protocol, it is assumed that Data Partner 0 has the response variable(s) and potentially some covariates, while it is assumed that Data Partner 1 has at least one covariate. For this vignette, we let Data Partner 0 have the covariates stored in columns 5 through 7 of vdra_data and Data Partner 1 has the covariates stored in columns 8 through 11.
Once pmn() is running, proceed to the section indicating the regression you wish to perform.
In order to perform linear regression in a 2-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first.
library(vdra)
fit = AnalysisCenter.2Party(regression = "linear",
data = vdra_data[, c(1, 5:7)],
response = "Change_BMI",
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner.2Party(regression = "linear",
data = vdra_data[, 8:11],
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)After a few minutes, you should see the following output for both parties.
## Party Estimate Std. Error t value Pr(>|t|)
## (Intercept) dp0 2.284e+01 1.620344 1.409e+01 < 2.22e-16 ***
## Exposure dp0 -5.779e+00 0.394282 -1.466e+01 < 2.22e-16 ***
## Age dp0 2.024e-01 0.020086 1.007e+01 < 2.22e-16 ***
## ComorbidScore dp0 2.626e-01 0.106151 2.474e+00 0.0133813 *
## NumRx dp1 -1.324e-01 0.096882 -1.367e+00 0.1717263
## BMI_pre dp1 -1.176e-02 0.021796 -5.394e-01 0.5896362
## Race:Race 1 dp1 2.108e+00 0.788397 2.673e+00 0.0075283 **
## Race:Race 2 dp1 1.675e+00 0.740472 2.262e+00 0.0237404 *
## Race:Race 3 dp1 3.641e+00 0.733589 4.964e+00 7.1126e-07 ***
## Race:Race 4 dp1 4.722e+00 0.738904 6.391e+00 1.7827e-10 ***
## Race:Race 5 dp1 4.033e-02 0.746852 5.400e-02 0.9569363
## Sex:M dp1 -1.244e+00 0.563097 -2.208e+00 0.0272501 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 14.92 on 5728 degrees of freedom
## Multiple R-squared: 0.06851 , Adjusted R-squared: 0.06672
## F-statistic: 38.3 on 11 and 5728 DF, p-value: < 2.22e-16The output is similar if we had used lm():
##
## Call:
## lm(formula = Change_BMI ~ ., data = vdra_data[, c(1, 5:11)])
##
## Residuals:
## Min 1Q Median 3Q Max
## -37.935 -10.324 -1.444 8.571 77.989
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 22.83755 1.62034 14.094 < 2e-16 ***
## Exposure -5.77936 0.39428 -14.658 < 2e-16 ***
## Age 0.20235 0.02009 10.074 < 2e-16 ***
## ComorbidScore 0.26264 0.10615 2.474 0.01338 *
## NumRx -0.13242 0.09688 -1.367 0.17173
## BMI_pre -0.01176 0.02180 -0.539 0.58964
## RaceRace 1 2.10776 0.78840 2.673 0.00753 **
## RaceRace 2 1.67488 0.74047 2.262 0.02374 *
## RaceRace 3 3.64139 0.73359 4.964 7.11e-07 ***
## RaceRace 4 4.72205 0.73890 6.391 1.78e-10 ***
## RaceRace 5 0.04033 0.74685 0.054 0.95694
## SexM -1.24359 0.56310 -2.208 0.02725 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 14.92 on 5728 degrees of freedom
## Multiple R-squared: 0.06851, Adjusted R-squared: 0.06672
## F-statistic: 38.3 on 11 and 5728 DF, p-value: < 2.2e-16As with the linear regression, we are already running the following block of code in an R session.
In order to perform logistic regression in a 2-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first. Notice that this time we are using the binary variable WtLost as the response.
library(vdra)
fit = AnalysisCenter.2Party(regression = "logistic",
data = vdra_data[, c(2, 5:7)],
response = "WtLost",
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner.2Party(regression = "logistic",
data = vdra_data[, 8:11],
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)After a few minutes, you should see the following output:
## Party Estimate Std. Error t value Pr(>|t|)
## (Intercept) dp0 1.633e+00 0.377311 4.327351 1.5091e-05 ***
## Exposure dp0 -9.409e-01 0.099919 -9.416743 < 2.22e-16 ***
## Age dp0 3.772e-02 0.004815 7.833597 4.7411e-15 ***
## ComorbidScore dp0 3.653e-02 0.025524 1.431209 0.15237037
## NumRx dp1 -4.366e-02 0.023002 -1.898102 0.05768263 .
## BMI_pre dp1 -3.459e-03 0.005094 -0.679062 0.49709830
## Race:Race 1 dp1 3.164e-01 0.190301 1.662715 0.09636954 .
## Race:Race 2 dp1 4.087e-01 0.176844 2.311323 0.02081501 *
## Race:Race 3 dp1 4.870e-01 0.175991 2.767129 0.00565524 **
## Race:Race 4 dp1 6.556e-01 0.188746 3.473682 0.00051337 ***
## Race:Race 5 dp1 -2.440e-01 0.153508 -1.589724 0.11189697
## Sex:M dp1 -3.154e-01 0.139085 -2.267681 0.02334863 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispertion parameter for binomial family taken to be 1)
##
## Null Deviance: 3530 on 5739 degrees of freedom
## Residual deviance: 3311 on 5728 degrees of freedom
## AIC: 3335
## BIC: 3415
##
## Number of Newton-Raphson iterations: 7The output is similar if we had used glm():
##
## Call:
## glm(formula = WtLost ~ ., family = binomial, data = vdra_data[c(2,
## 5:11)])
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.8468 0.2797 0.3737 0.4848 1.0130
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.632756 0.377298 4.327 1.51e-05 ***
## Exposure -0.940912 0.099913 -9.417 < 2e-16 ***
## Age 0.037721 0.004815 7.834 4.73e-15 ***
## ComorbidScore 0.036530 0.025523 1.431 0.152356
## NumRx -0.043661 0.023001 -1.898 0.057674 .
## BMI_pre -0.003459 0.005094 -0.679 0.497085
## RaceRace 1 0.316417 0.190294 1.663 0.096357 .
## RaceRace 2 0.408743 0.176838 2.311 0.020811 *
## RaceRace 3 0.486991 0.175986 2.767 0.005654 **
## RaceRace 4 0.655642 0.188734 3.474 0.000513 ***
## RaceRace 5 -0.244035 0.153505 -1.590 0.111890
## SexM -0.315401 0.139079 -2.268 0.023343 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 3530.2 on 5739 degrees of freedom
## Residual deviance: 3310.6 on 5728 degrees of freedom
## AIC: 3334.6
##
## Number of Fisher Scoring iterations: 5As with the linear regression, we are already running the following block of code in an R session.
In order to perform Cox regression in a 2-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first. Notice that this time we are using the two variables for the response: Time which measures the time to event and the binary variable Status which records if the event happened or was censored.
library(vdra)
fit = AnalysisCenter.2Party(regression = "cox",
data = vdra_data[, c(3:4, 5:7)],
response = c("Time", "Status"),
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner.2Party(regression = "cox",
data = vdra_data[, 8:11],
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)After a few minutes, you should see the following output:
## n= 5740, number of events= 4127
##
## party coef exp(coef) se(coef) z Pr(>|z|)
## Exposure dp0 -0.046067 0.954978 0.031227 -1.475201 0.140158
## Age dp0 0.002521 1.002524 0.001567 1.608509 0.107724
## ComorbidScore dp0 -0.004967 0.995045 0.008322 -0.596861 0.550600
## NumRx dp1 -0.004932 0.995081 0.007601 -0.648776 0.516483
## BMI_pre dp1 0.058895 1.060664 0.001615 36.457746 < 2e-16 ***
## Race:Race 1 dp1 -0.054626 0.946839 0.062410 -0.875274 0.381425
## Race:Race 2 dp1 0.019202 1.019388 0.058428 0.328648 0.742422
## Race:Race 3 dp1 0.098094 1.103067 0.056990 1.721246 0.085206 .
## Race:Race 4 dp1 0.024423 1.024724 0.058176 0.419815 0.674621
## Race:Race 5 dp1 -0.120371 0.886592 0.060084 -2.003364 0.045138 *
## Sex:M dp1 0.011307 1.011371 0.044496 0.254116 0.799406
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## party exp(coef) exp(-coef) lower .95 upper .95
## Exposure dp0 0.954978 1.047144 0.898282 1.015253
## Age dp0 1.002524 0.997482 0.999449 1.005608
## ComorbidScore dp0 0.995045 1.004980 0.978947 1.011408
## NumRx dp1 0.995081 1.004944 0.980365 1.010017
## BMI_pre dp1 1.060664 0.942806 1.057311 1.064028
## Race:Race 1 dp1 0.946839 1.056145 0.837824 1.070040
## Race:Race 2 dp1 1.019388 0.980981 0.909087 1.143071
## Race:Race 3 dp1 1.103067 0.906563 0.986488 1.233423
## Race:Race 4 dp1 1.024724 0.975873 0.914298 1.148487
## Race:Race 5 dp1 0.886592 1.127915 0.788098 0.997396
## Sex:M dp1 1.011371 0.988757 0.926906 1.103533
##
## Concordance= 0.6607 (se = 0.004373 )
## Likelihood ratio test= 1194 on 11 df, p= < 2.22e-16
## Wald test = 1354 on 11 df, p= < 2.22e-16
## Score test = 1378 on 11 df, p= < 2.22e-16
##
## Number of Newton-Raphson iterations: 5The output is similar if we had used coxph() in the survival package:
## Call:
## coxph(formula = Surv(Time, Status) ~ ., data = vdra_data[, 3:11])
##
## n= 5740, number of events= 4127
##
## coef exp(coef) se(coef) z Pr(>|z|)
## Exposure -0.046067 0.954978 0.031227 -1.475 0.1402
## Age 0.002521 1.002524 0.001567 1.609 0.1077
## ComorbidScore -0.004967 0.995045 0.008322 -0.597 0.5506
## NumRx -0.004932 0.995081 0.007601 -0.649 0.5165
## BMI_pre 0.058895 1.060664 0.001615 36.458 <2e-16 ***
## RaceRace 1 -0.054626 0.946839 0.062410 -0.875 0.3814
## RaceRace 2 0.019202 1.019388 0.058428 0.329 0.7424
## RaceRace 3 0.098094 1.103067 0.056990 1.721 0.0852 .
## RaceRace 4 0.024423 1.024724 0.058176 0.420 0.6746
## RaceRace 5 -0.120371 0.886592 0.060084 -2.003 0.0451 *
## SexM 0.011307 1.011371 0.044496 0.254 0.7994
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## Exposure 0.9550 1.0471 0.8983 1.0153
## Age 1.0025 0.9975 0.9994 1.0056
## ComorbidScore 0.9950 1.0050 0.9789 1.0114
## NumRx 0.9951 1.0049 0.9804 1.0100
## BMI_pre 1.0607 0.9428 1.0573 1.0640
## RaceRace 1 0.9468 1.0561 0.8378 1.0700
## RaceRace 2 1.0194 0.9810 0.9091 1.1431
## RaceRace 3 1.1031 0.9066 0.9865 1.2334
## RaceRace 4 1.0247 0.9759 0.9143 1.1485
## RaceRace 5 0.8866 1.1279 0.7881 0.9974
## SexM 1.0114 0.9888 0.9269 1.1035
##
## Concordance= 0.661 (se = 0.004 )
## Likelihood ratio test= 1194 on 11 df, p=<2e-16
## Wald test = 1354 on 11 df, p=<2e-16
## Score (logrank) test = 1378 on 11 df, p=<2e-16For 2T-party Vertically Distributed Regression, we will run four sessions of R simultaneously. If you are using R-Studio, you can open up three more sessions of R-Studio by choosing the menu item Session→New Session. The first session will run the PopMedNet Simulator, pmn(), and the other three sessions will run the analysis center (Data Partner 0), Data Partner 1, and Data Partner 2, respectively. Once you run one block of code in a session of R, immediately move to the next R session to execute the next block of code. The scripts interact in such a way that they all need to run in parallel for the the computation to proceed to completion.
In our code, we assume that we run pmn() first, as this simulates PopMedNet being run first, which delivers the requests in a real-world setting. Before you run pmn(), be sure that ~/vdra is empty (or at least does not contain any files of the form *.ok). When we run pmn(), we tell it that there will be one data partner beyond the analysis center and that the working directory is ~/vdra.
At this point, pmn() will have created directories ~/vdra/dp0, ~/vdra/dp1, and ~/vdra/dp2 which are used in the communication process. For this protocol, it is assumed that the analysis center has no data, Data Partner 1 has the response variable(s) and potentially some covariates, and that Data Partner 2 has at least one covariate. For this vignette, we let Data Partner 1 have the covariates stored in columns 5 through 7 of vdra_data and Data Partner 2 has the covariates stored in columns 8 through 11.
Once pmn() is running, proceed to the section indicating the regression you wish to perform.
In order to perform linear regression in a 2T-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first.
library(vdra)
fit = AnalysisCenter.3Party(regression = "linear",
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner1.3Party(regression = "linear",
data = vdra_data[, c(1, 5:7)],
response = "Change_BMI",
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)Finally, run the following code in the fourth R session simultaneously with the other two R sessions. This code is for Data Partner 2.
library(vdra)
fit = DataPartner2.3Party(regression = "linear",
data = vdra_data[, 8:11],
monitorFolder = "~/vdra/dp2",
popmednet = FALSE)
summary(fit)After a few minutes, you should see the same output as in the 2-party scenario.
As with linear regression, we are already running the following block of code in an R session.
In order to perform logistic regression in a 2T-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first. Notice that this time we are using the binary variable WtLost as the response.
library(vdra)
fit = AnalysisCenter.3Party(regression = "logistic",
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner1.3Party(regression = "logistic",
data = vdra_data[, c(2, 5:7)],
response = "WtLost",
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)Finally, run the following code in the fourth R session simultaneously with the other two R sessions. This code is for Data Partner 2.
library(vdra)
fit = DataPartner2.3Party(regression = "logistic",
data = vdra_data[, 8:11],
monitorFolder = "~/vdra/dp2",
popmednet = FALSE)
summary(fit)After a few minutes, you should see the same output as in the 2-party scenario
As with linear regression, we are already running the following block of code in an R session.
In order to perform Cox regression in a 2T-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first. Notice that this time we are using the two variables for the response: Time which measures the time to event and the binary variable Status which records if the event happened or was censored.
library(vdra)
fit = AnalysisCenter.3Party(regression = "cox",
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner1.3Party(regression = "cox",
data = vdra_data[, c(3:4, 5:7)],
response = c("Time", "Status"),
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)Finally, run the following code in the fourth R session simultaneously with the other two R sessions. This code is for Data Partner 2.
library(vdra)
fit = DataPartner2.3Party(regression = "cox",
data = vdra_data[, 8:11],
monitorFolder = "~/vdra/dp2",
popmednet = FALSE)
summary(fit)After a few minutes, you should see the same output as in the 2-party scenario
For k-party Vertically Distributed Regression, we are not limited to two data partners beyond the analysis center, but we can have any number. In fact, we have successfully run this program for k = 10 data partners. However, for the sake of this vignette, we will restrict ourselves to just two and note that we would only have to change the value of numDataPartners. For example, if we had k = 10 data partners, we would need to set numDataPartners = 10 in each of the following code blocks. Since we have two data partners, we will run four sessions of R simultaneously. If you are using R-Studio, you can open up three more sessions of R-Studio by choosing the menu item Session→New Session. The first session will run the PopMedNet Simulator, pmn(), and the other three sessions will run the analysis Center (Data Partner 0), Data Partner 1, and Data Partner 2, respectively. Once you run one block of code in a session of R, immediately move to the next R session to execute the next block of code. The scripts interact in such a way that they all need to run in parallel for the the computation to proceed to completion.
In our code, we assume that we run pmn() first, as this simulates PopMedNet being run first, which delivers the requests in a real-world setting. Before you run pmn(), be sure that ~/vdra is empty (or at least does not contain any files of the form *.ok). When we run pmn(), we tell it that there will be one data partner beyond the analysis center and that the working directory is ~/vdra.
At this point, pmn() will have created directories ~/vdra/dp0, ~/vdra/dp1, and ~/vdra/dp2 which are used in the communication process. For this protocol, it is assumed that the analysis center has no data, Data Partner 1 has the response variable(s) and potentially some covariates, and that Data Partner 2 has at least one covariate. For this vignette, we let Data Partner 1 have the covariates stored in columns 5 through 7 of vdra_data and Data Partner 2 has the covariates stored in columns 8 through 11.
Once pmn() is running, proceed to the section indicating the regression you wish to perform.
In order to perform linear regression in a KT-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first.
library(vdra)
fit = AnalysisCenter.KParty(regression = "linear",
numDataPartners = 2,
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner.KParty(regression = "linear",
data = vdra_data[, c(1, 5:7)],
response = "Change_BMI",
numDataPartners = 2,
dataPartnerID = 1,
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)Finally, run the following code in the fourth R session simultaneously with the other two R sessions. This code is for Data Partner 2.
library(vdra)
fit = DataPartner.KParty(regression = "linear",
data = vdra_data[, 8:11],
numDataPartners = 2,
dataPartnerID = 2,
monitorFolder = "~/vdra/dp2",
popmednet = FALSE)
summary(fit)As with linear regression, we are already running the following block of code in an R session.
In order to perform logistic regression in a KT-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first. Notice that this time we are using the binary variable WtLost as the response.
library(vdra)
fit = AnalysisCenter.KParty(regression = "logistic",
numDataPartners = 2,
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner.KParty(regression = "logistic",
data = vdra_data[, c(2, 5:7)],
response = "WtLost",
numDataPartners = 2,
dataPartnerID = 1,
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)Finally, run the following code in the fourth R session simultaneously with the other two R sessions. This code is for Data Partner 2.
library(vdra)
fit = DataPartner.KParty(regression = "logistic",
data = vdra_data[, 8:11],
numDataPartners = 2,
dataPartnerID = 2,
monitorFolder = "~/vdra/dp2",
popmednet = FALSE)
summary(fit)As with linear regression, we are already running the following block of code in an R session.
In order to perform Cox regression in a KT-party setting run the following code in the second R session simultaneously with the first R session. This code is for the analysis center (Data Partner 0). In reality, it does not matter which data partner is run first. Notice that this time we are using the two variables for the response: Time which measures the time to event and the binary variable Status which records if the event happened or was censored.
library(vdra)
fit = AnalysisCenter.KParty(regression = "cox",
numDataPartners = 2,
monitorFolder = "~/vdra/dp0",
popmednet = FALSE)
summary(fit)Now, run the following code in the third R session simultaneously with the other two R sessions. This code is for Data Partner 1.
library(vdra)
fit = DataPartner.KParty(regression = "cox",
data = vdra_data[, c(3:4, 5:7)],
response = c("Time", "Status"),
numDataPartners = 2,
dataPartnerID = 1,
monitorFolder = "~/vdra/dp1",
popmednet = FALSE)
summary(fit)Finally, run the following code in the fourth R session simultaneously with the other two R sessions. This code is for Data Partner 2.
library(vdra)
fit = DataPartner.KParty(regression = "cox",
data = vdra_data[, 8:11],
numDataPartners = 2,
dataPartnerID = 2,
monitorFolder = "~/vdra/dp2",
popmednet = FALSE)
summary(fit)In order to facilitate the the user to further analyze the data and the model, four utilities have been provided. We present these for each of the three types of regression that we perform.
For linear regression, we allow the creation of sub-models. As an example, we have stored the output of the distributed linear regression (either 2-party, 2T-party, or KT-party) from the data partner which holds the response in vdra_fit_linear_A (which comes with the package). We can check the fit of different sub-models as shown in the following script. All data partners can use this function. The first argument is a standard R formula using the variables that are found in the fit, and the second argument is the results of the regression.
## Party Estimate Std. Error t value Pr(>|t|)
## (Intercept) dp0 3.707e+01 0.956664 38.746947 < 2e-16 ***
## Change_BMI dp0 8.604e-02 0.008540 10.074380 < 2e-16 ***
## Exposure dp0 2.481e-01 0.261858 0.947364 0.343493
## ComorbidScore dp0 -5.007e-02 0.069252 -0.723004 0.469707
## NumRx dp1 7.715e-02 0.063176 1.221213 0.222056
## BMI_pre dp1 -9.351e-03 0.014212 -0.657944 0.510600
## Race:Race 1 dp1 1.297e-01 0.514410 0.252062 0.801002
## Race:Race 2 dp1 9.192e-01 0.482905 1.903412 0.057037 .
## Race:Race 3 dp1 -1.663e-01 0.479376 -0.347000 0.728604
## Race:Race 4 dp1 8.517e-01 0.483403 1.761807 0.078155 .
## Race:Race 5 dp1 6.624e-01 0.486924 1.360370 0.173766
## Sex:M dp1 4.415e-01 0.367290 1.202165 0.229349
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.732 on 5728 degrees of freedom
## Multiple R-squared: 0.01999 , Adjusted R-squared: 0.01811
## F-statistic: 10.62 on 11 and 5728 DF, p-value: < 2.22e-16## Party Estimate Std. Error t value Pr(>|t|)
## (Intercept) dp0 23.473918 0.858507 27.3427 < 2.22e-16 ***
## Exposure dp0 -5.683961 0.397325 -14.3056 < 2.22e-16 ***
## Age dp0 0.204154 0.020230 10.0918 < 2.22e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.05 on 5737 degrees of freedom
## Multiple R-squared: 0.05128 , Adjusted R-squared: 0.05095
## F-statistic: 155 on 2 and 5737 DF, p-value: < 2.22e-16## Party Estimate Std. Error t value Pr(>|t|)
## (Intercept) dp0 31.65929 0.283832 111.5424 < 2.22e-16 ***
## Exposure dp0 -5.73301 0.400771 -14.3050 < 2.22e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.18 on 5738 degrees of freedom
## Multiple R-squared: 0.03443 , Adjusted R-squared: 0.03427
## F-statistic: 204.6 on 1 and 5738 DF, p-value: < 2.22e-16fit4 = differentModel(Change_BMI ~ Exposure + Age + `Sex:M` + `Race:Race 1`, vdra_fit_linear_A)
summary(fit4)## Party Estimate Std. Error t value Pr(>|t|)
## (Intercept) dp0 24.870147 0.927739 26.807267 < 2.22e-16 ***
## Exposure dp0 -5.704460 0.396184 -14.398517 < 2.22e-16 ***
## Age dp0 0.204923 0.020174 10.157533 < 2.22e-16 ***
## Sex:M dp1 -2.582645 0.489395 -5.277216 1.3598e-07 ***
## Race:Race 1 dp1 -0.467666 0.561828 -0.832401 0.40522
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.01 on 5735 degrees of freedom
## Multiple R-squared: 0.05714 , Adjusted R-squared: 0.05649
## F-statistic: 86.89 on 4 and 5735 DF, p-value: < 2.22e-16For logistic regression, we can perform both the Hosmer-Lemeshow goodness of fit test for logistic regression and plot the receiver operating curve (ROC). We run these tests on vdra_fit_logistic_A, which is the results of the distributed logistic regression (either 2-party, 2T-party, or KT-party) as seen by the data partner which holds the response. Only the data partner which holds the response can run these functions. In both cases, the second argument is optional and is the number or groups, or bins, on which to perform the analysis.
## Hosmer and Lemeshow goodness of fit (GOF) test
## Chi-squared: 4.167579 with DF 8, p-value: 0.8416962## Hosmer and Lemeshow goodness of fit (GOF) test
## Chi-squared: 41.12232 with DF 48, p-value: 0.7484554

We can compute the survival curve for a distributed Cox regression (either 2-party, 2T-party, or KT-party). This function is works similar to survfit() in the survival package. The results can be both printed and plotted. Only the data partner which holds the response can run this function. The plot command takes only takes the plotting parameters: xlim, ylim, xlab, ylab, and main.
## n events
## 5740 4127
# Calculate the results based on strat that the data partner with the response holds
sf = survfitDistributed(vdra_fit_cox_A, ~ Exposure, data = vdra_data[c(3:4, 5:7)])
print(sf)## n events
## Exposure=0 2861 2076
## Exposure=1 2879 1968# plot both curves in the same plot
plot(sf, xlim = c(0, 400), ylim = c(0, 1),
xlab = "Time to Event", ylab = "Survival Percentage",
main = "BMI Study")

